Data Analysis
Introduction
To provide additional transparency and to minimize the “black box” effect of using tools and libraries with which I and any readers may have varying levels of expertise, I will start with one common dataset and discuss the actions I take with each tool.
The data I used for analysis was output in the form of a XLS content inventory from Digital Commons, an institutional repository software by bepress that Marshall University uses to provide access to finding aids and access documents as well as digitized and born digital materials from the department’s university archives and manuscript collections. In the resulting spreadsheet, each field is represented by a column and each item is represented by a row. I chose to focus on the metadata for the 8,200 items digitized from our manuscript collections because that was my primary area of focus for the archivist portion of my position as an Archivist and Digital Preservation Librarian.
I split the original data linked above into two overlapping subsets: one which I would analyze in Excel and another in which I would analyze using the tools I outline below.
First: Excel
Before I dig into analyzing any dataset, I believe it’s important to get a sense what is present, especially when I’m new to working with the collections belonging to a particular institution. To do this, I chose to do a basic overview of select data in Excel, which gave me a chance to decide what data I would analyze for this portion of the project and how I would analyze that data. In doing an initial analysis as Excel, I chose to focus on the most consistently used and categorical fields that do not lend themselves to word frequency or other types of analyses. Specifically, I examined the format, date, place, creator, and collection from which each digitized item originated. Of those fields, I retained creator and collection for use with tools other than Excel.
Though I will synthesize my main takeaways from that analysis here, I expand upon the analysis on a dedicated Excel page. Additionally, on that page I created initial exploratory graphs from the complete dataset to visualize the data.
The larger messages and pieces of information I took away from this specific analysis are:
- What collections are most represented in our digitized materials. I can use my knowledge of the content of these collections to inform my understanding of the broader analysis of word embeddings and frequencies I get from other tools. The most represented collection, composing 12.92% of digitized materials, comes from the Cabell-Wayne Historical Society Collection that focuses exclusively on local Huntington, WV and area history. The second most represented collection, at 12.44% is the Fred B. Lambert Papers which has a nearly identical focus. This means that I need to keep in mind how these two collections, which consist of 25.36% of total digitized collections, will impact the shape and representation within our materials.
- What formats are represented and underrepresented in our digitized collections. Only 8.29% of materials can be classed as non-visual materials, with photographs representing 70.83% of digitized items. Such a distinctly overwhelming proportion indicates that photographs and visual materials were a higher priority for digitization due to perceived ease of description. Within the department, there was limited searchability of textual materials based on prior available technologies, in terms of available content management systems and lack of ability to bulk perform OCR.
Beyond Excel and a Note About Stopwords
The data I used for analysis using tools beyond Excel primarily focused on data that is less categorical and more subjective, but did include more systematic data such as the creator of the item as well as the collection from which the item came. The dataset included the name of the collection from which the item was digitized, description (referred to as “abstract” within the spreadsheet–this is a fixed internal use name within Digital Commons), authors (i.e. creators), subject (subject headings for people, places, and studio that took the photograph), and title.
Using metadata as data for text analysis also requires certain special considerations. Unlike the natural language that composes most texts that undergo text analysis, metadata has unique characteristics that are not present in typical texts such as books, articles, and other formats–namely, it is comparitively brief, broken into distinct fields, and relies on non-natural conventions of language use. Computational approaches to text analysis often do not know how to make sense of these texts without careful consideration of terms or constructs that typical text analysis approaches would find significant.
These conventions mean that relying on stopword lists built into various tools can be incredibly risky. As such, I chose to create and use my own stopword list when analyzing this text. To rewind a bit: Stop words are words that are removed from a dataset prior to or after processing and analyzing the data. Typically, most tools have unseen stop word lists that are built in to them that remove common words (a, an, then) and characters (, . ! ?). While the removal of such terms helps to rid the dataset of “noise” that obfuscates target areas of analysis, the nature of metadata means that stopword lists that are helpful for natural language processing tasks are not suitable for adapted purposes. Such an issue is further compounded by the fact that archives are often home to hyper local subjects that become noise that cannot be predicted by generic stopword lists. As a result, I had to create a tailored list of stopwords to use with the dataset. The stopwords I used for my dataset can be found in the project files.
AntConc
As mentioned previously, taking a collections as data approach tends to only surface the individuals and subjects most represented, neglecting to consider what is not represented and why a particular topic is not represented. AntConc is a tool that allows the viewer to use a directory of text files as a focus for computational text analysis by focusing on word frequencies and concordances, also understood as the words that appear before or after a particular word. In this project, the focus was a directory of text files where each text file was the equivalent of one metadata record. Using this tool, I was able to discover the most frequent words used and the context in which they were used. Some were unsurprising given the scope of the collection: Huntington and West Virginia were often used in context together and both were among the most represented words.
However, I was able to surface some issues that I did not anticipate at the beginning of the project. While I did not expressly state that I was going to examine issues of gender as part of this project, one of the most frequently used words in the collection was “mrs.” I examined the words that appeared frequently in conjunction with that title and was in for a surprise, seen in the following screenshot from AntConc:
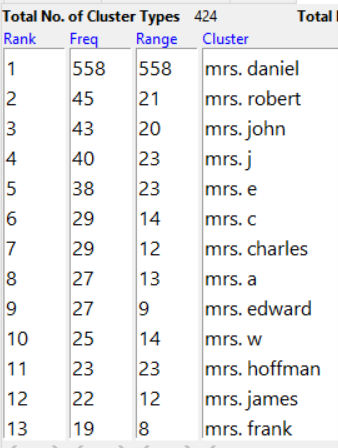
The above screenshot demonstrates that the majority of uses of the term “mrs.” only featured the mid to late twentieth century use of the term, which was used in conjunction with a woman’s husband’s name as an identifier for the woman. The screenshot demonstrates that nearly all women were “nameless” and only identified by “mrs.” in conjunction with the name of their husband. Remediating such an issue would require additional research beyond the scope of this project.
Topic Modeling Tool
The Topic Modeling Tool takes as input a directory of files as well, just like AntConc. The Topic Modeling Tool will then output a pre-specified number of topics each composed of twenty terms. Researchers are then charged with examining the collections of words for each topic and ascribing meaning. This tool was unsuccessful when used in the context of this project because the size of each metadata record did not provide enough baseline textual data to output coherent topics. Instead, the Topic Modeling Tool output topics that were composed of multiple discrete subjects that merely featured overly common words, such as “Huntington”, items that were created during a shared year, or even simply items from the same collection that are often on the same topic given the nature of the broader collection. Given that the records primarily described visual materials with limited textual components, this tool would be more appropriately used with transcribed letters or more extensive (but still brief) textual data. Alternative uses of topic modeling could be done at the collection level as a subset of the larger archive of materials, but this was beyond the scope of a more global project.
To see an example, look at a sample of twenty topics output below:
List of Topics
- enslow catherine bliss papers terms people subject white va 0010 huntington beckley mrs back virginia reads 0255 police black greenbrier
- henderson cam college subject terms memorial field house marshall ca huntington people papers camden white morrow back va eli 0391
- dr hoffman charles carl hospital medical terms people subject collection baxter 1904 personnel anthony 1981 curtis 0189 association 1972 richard
- art card greeting norcross original collection daniel mrs dr sharkey 0842 terms christmas subject watercolor color pastels acrylic unknown company
- huntington va ave st collection 3rd subject terms day 4th street 1937 wva engineers aerial avenue corps west photo 5th
- flood 1937 jane huntington war 1918 italian world wwi terms floods subject 1913 merrill hastings wva shepherd front papers store
- huntington va church marshall photograph university lantern 0227 regional slide subject victor terms animatograph ca collection studio people presbyterian newcomb
- people subject terms reese african matthew kennedy carl barnett black photograph collection 0853 original americans sleeve john political johnson studio
- school myers high huntington va subject terms family schools collection 1951 reads back county alexander people cabell helen 0787 1
- family people unidentified subject terms papers studio ca mary back reads col backprint visite de glanville charles 1860 note john
- memphis dickinson subject garrison terms people earl papers tennessee war military wwii marine long photo theater world 1945 marines pacific
- confederate war blake rosanna civil 1865 1861 collection states subject 0703 terms people america robert gen lee studio de carte
- hughes subject terms papers revella mark freeman lee people coal ca howard photo cuba james uss mine back missile studio
- lambert fred 1964 1809 0236 papers history va box local genealogy ms notebook bussey 76 barboursville property people subject terms
- mrs huntington club miller wv terms subject doris back people woman reads wayne 0525 bridge papers david county creek hupco
- railroad railroads va terms ky subject huntington valley collection car rr ohio big station railway american sandy river guyan chesapeake
- va postcard subject terms collection 9 cm 14 col postmarked addressed clifford 0596 caverlee view west virginia postmark addressee john
- cabell wayne society historical 0099 collection huntington va stone marvin people terms subject studio house 5cm barta 1 studios photograph
- roosevelt franklin delano smith papers president jean people subject 1945 back terms reads presidents 1933 edward ed label photos eleanor
- va terms subject ca william river ohio back guyandotte reads wallace white black cabell 1900 house steamboat papers boats photograph